Today, the Web is one of the world’s largest databases. However, due to its textual nature, aggregating and analyzing textual data from the Web analogue to a data warehouse is a hard problem. For instance, users may start from huge amounts of textual data and drill down into tiny sets of specific factual data, may manipulate or share atomic facts, and may repeat this process in an iterative fashion.
In the GoOLAP project we investigate fundamental problems in the process: What are common analysis operations of “end users” on natural language Web text? What is the typical iterative process for generating, verifying and sharing factual information from plain Web text? Can we integrate both, the “cloud”, a cluster of massively parallel working machines, and the “crowd”, end users of GoOLAP.info, for solving hard problems, such as training 10.000s of fact extractors, for verifying billions of atomic facts or for generating analytical reports from the Web?
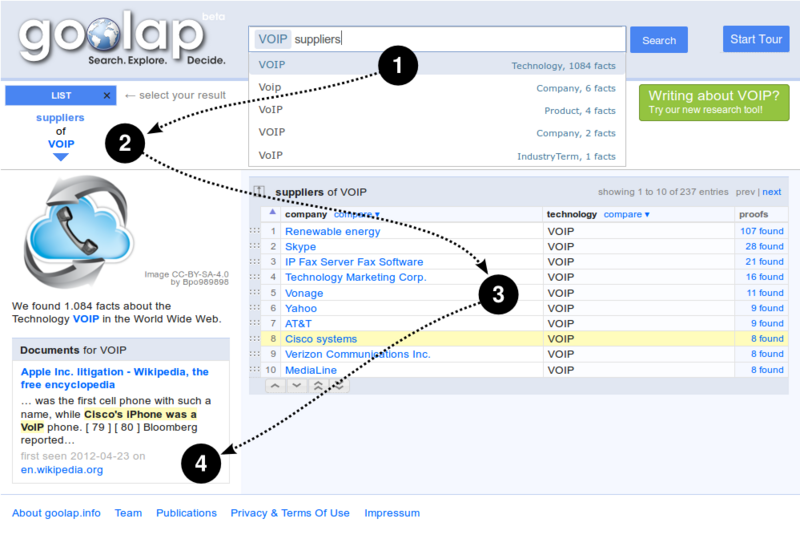
The current prototype GoOLAP.info contains already factual information from the Web for about several million objects. The keyword-based query interface focuses on simple query intentions, such as, “display everything about Airbus” or complex aggregation intentions, such as “List and compare mergers, acquisitions, competitors and products of airplane technology vendors”. Start your own analysis at GoOLAP.info
The GOOLAP research project is conducted with students from the BHT.
Publications
- Sebastian Arnold, Alexander Löser, Torsten Kilias: Resolving Common Analytical Tasks in Text Databases. DOLAP 2015: 75-84
- Alexander Löser, Christoph Nagel, Stephan Pieper, Christoph Boden: Beyond search: Retrieving complete tuples from a text-database. Information Systems Frontiers 15(3): 311-329 (2013)
- Alexander Löser, Sebastian Arnold, Tillmann Fiehn: The GoOLAP Fact Retrieval Framework. eBISS 2011: 84-97
- Christoph Boden, Alexander Löser, Christoph Nagel, Stephan Pieper: FactCrawl: A Fact Retrieval Framework for Full-Text Indices. WebDB 2011