Textual data is now a core source of information in the enterprise. Example applications are monitoring social networks for market research, managing data in call centers for enhancing customer support or analyzing customer feedback from cooperate forums for obtaining feedback for product development.
Having relational information from text data available, with low costs for extracting and organizing, provides knowledge workers and decision makers in an organization with insights that have, until now, not existed.
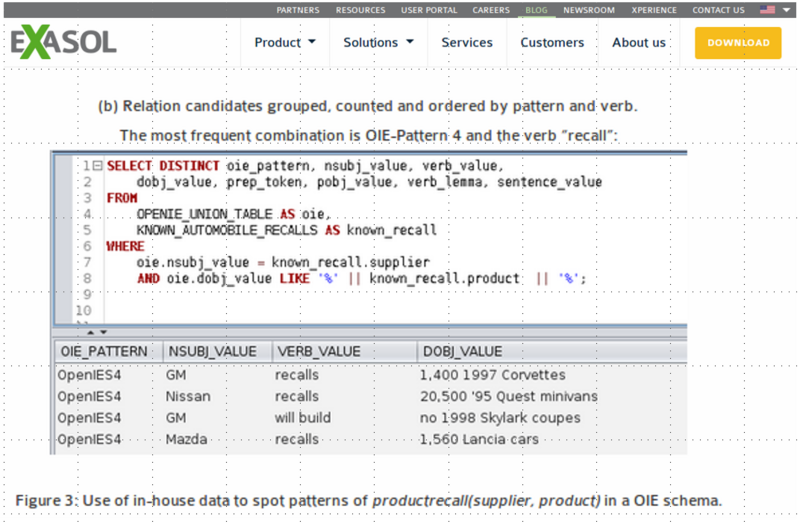
We propose the INDREX system that enables these users for the first time describing relation extraction tasks across documents and relational data in the RDBMS with SQL. INDREX extends a standard RDBMS with a set of white-box user-defined-functions that enable corpus-wide transformations from sentences into relations. As a result, (1) the user can leverage existing data from the RDBMS to further adapt extraction rules for text data to the target domain, (2) the user does not need an additional system for rule extraction and (3) the INDREX system can leverage the full power of built-in indexing and query optimization techniques of the underlaying RDBMS.
Publications
- "IDEL: In-Database Neural Entity Linking" was selected as Best Paper Award winner at IEEE BigComp 2019 in February 2019.
- Rudolf Schneider, Cordula Guder, Torsten Kilias, Alexander Löser, Jens Graupmann and Oleksandr Kozachuk: Interactive Relation Extraction in Main Memory Database Systems. COLING (Demos) 2016
- Torsten Kilias, Alexander Löser, Periklis Andritsos: INDREX: In-database relation extraction. Inf. Syst. 53: 124-144 (2015)
- Johannes Kirschnick, Torsten Kilias, Holmer Hemsen, Alexander Löser, Peter Adolphs, Heiko Ehrig, Holger Düwiger: A Marketplace for Web Scale Analytics and Text Annotation Services. COLING (Demos) 2014: 100-104
- Torsten Kilias, Alexander Löser, Periklis Andritsos: INDREX: in-database distributional relation extraction. DOLAP 2013: 93-100
Please see also our slide deck or the article at the Cloudera Blog on Text Mining with IMPALA or our article on iteractive relation extraction with Exasol.